
I’ve become convinced that “little languages”–small languages designed to solve very specific problems–are the future of programming, particularly after reading Gabriella Gonzalez’s The end of history for programming and watching Alan Kay’s Programming and Scaling talk. You should go check them out because they’re both excellent, but if you stick around I’ll explain just what I mean by “little languages” and why they’re important.
What is a “little language”?
I believe Jon Bentley coined the term “little language” in the eponymous Little Languages article, where he gave the following definition:
[…] a little language is specialized to a particular problem domain and does not include many features found in conventional languages.
For example, SQL is a little language for describing database operations. Regular expressions is a little language for text matching. Dhall is a little language for configuration management, and so on.
There are a few other names for these languages: Domain-specific languages (DSL:s), problem-oriented languages, etc. However, I like the term “little languages”, partially because the term “DSL” has become overloaded to mean anything from a library with a fluent interface to a full-blown query language like SQL, but also because “little languages” emphasizes their diminutive nature.
Why do we need little languages?
If you look at software today, through the lens of the history of engineering, it’s certainly engineering of a sort–but it’s the kind of engineering that people without the concept of the arch did. Most software today is very much like an Egyptian pyramid with millions of bricks piled on top of each other, with no structural integrity, but just done by brute force and thousands of slaves.
– Alan Kay, from A Conversation with Alan Kay
We have a real problem in the software engineering community: As an application grows in complexity its source code also grows in size. However, our capacity for understanding large code bases remains largely fixed. According to The Emergence of Big Code, a 2020 survey by Sourcegraph, the majority of respondents said that the size of their code base caused one or more of the following problems:
- Hard to onboard new hires
- Code breaks because of lack of understanding of dependencies
- Code changes become harder to manage
What’s worse, applications seem to grow at an alarming rate: Most respondents in the Sourcegraph survey estimated that their code base had grown between 100 to 500 times in the last ten years. As a concrete example, the Linux kernel started out at about 10 000 lines of code in 1992. Twenty years later, it weighs in at about 30 million lines 1.
Where does all this code come from? I don’t believe “more features” is sufficient to explain these increases in code volume; rather, I think it has to do with the way we build software. The general approach for adding new features to a program is to stack them on top of what you already have, not unlike how you would construct a pyramid. The problem is that–just like a pyramid–each subsequent layer will require more bricks than the last one.
Bucking the trend
Do you really need millions of lines of code to make a modern operating system? In 2006, Alan Kay and his collaborators in the STEPS program set out to challenge that assumption:
Science progresses by intertwining empirical investigations and theoretical models, so our first question as scientists is: if we made a working model of the personal computing phenomena could it collapse down to something as simple as Maxwell’s Equations for all of the electromagnetic spectrum, or the US Constitution that can be carried in a shirt pocket, or is it so disorganized (or actually complex) to require “3 cubic miles of case law”, as in the US legal system (or perhaps current software practice)? The answer is almost certainly in between, and if so, it would be very interesting if it could be shown to be closer to the simple end than the huge chaotic other extreme.
So we ask: is the personal computing experience (counting the equivalent of the OS, apps, and other supporting software) intrinsically 2 billion lines of code, 200 million, 20 million, 2 million, 200,000, 20,000, 2,000?
STEPS 2007 Progress Report, p. 4-5
Maxwell’s Equations, which Dr. Kay was referring to, is a set of equations that describe the foundations of electromagnetism, optics and electric circuits. A cool thing about them is that even though they have such a wide scope, they’re compact enough to fit on a t-shirt:
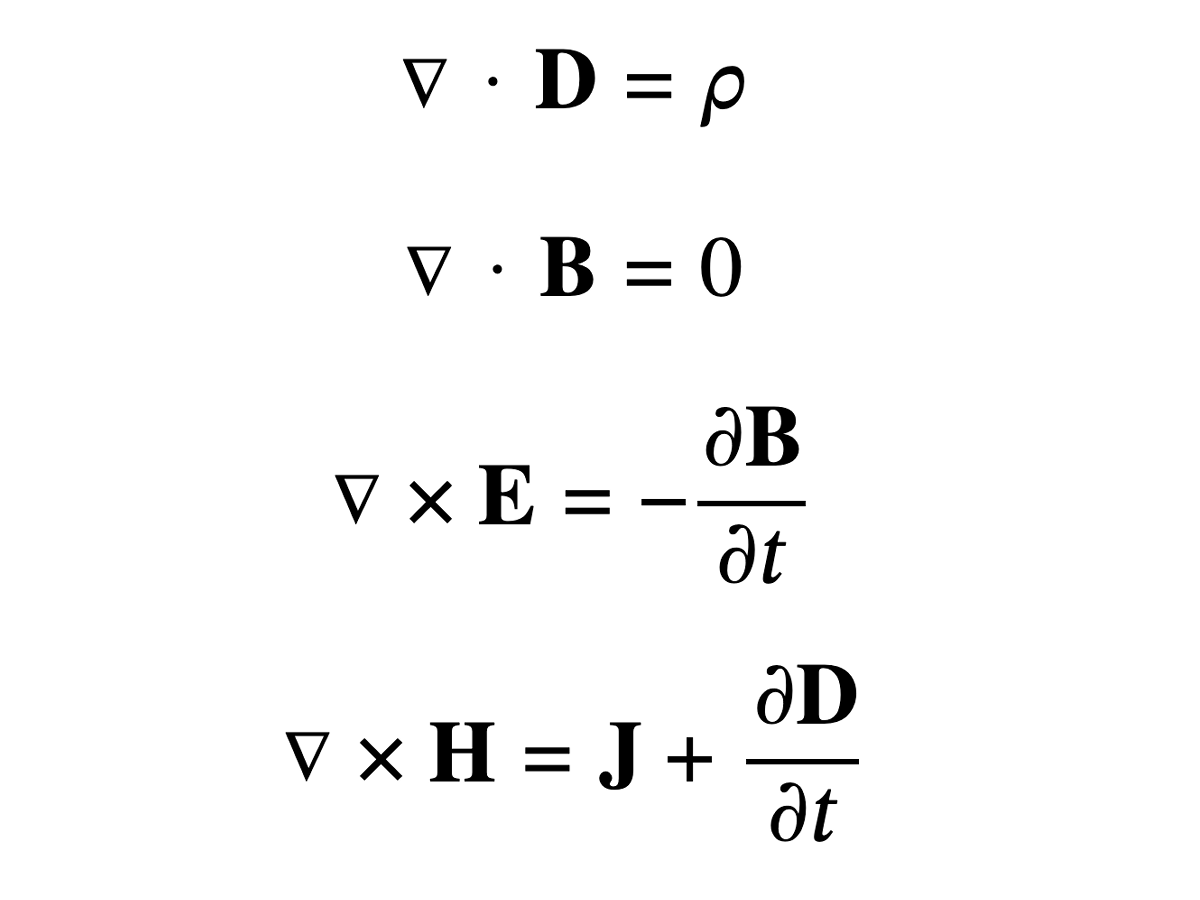
One reason they’re so terse is the use of the Del notation to describe vector calculus operations. Important to note is that Del isn’t really an operator–it’s more like a shorthand to make some equations in vector calculus easier to work with.
What if it’s possible to create the equivalent of Del notation for programming? Just as Del could help make vector calculus more manageable, are there notations that could help us reason about programs in much the same way? This question was one of the “powerful ideas” that powered the STEPS project:
We also think that creating languages that fit the problems to be solved makes solving the problems easier, makes the solutions more understandable and smaller, and is directly in the spirit of our “active-math” approach. These “problem-oriented languages” will be created and used for large and small problems, and at different levels of abstraction and detail.
The idea is that as you start to find patterns in your application, you can encode them in a little language–this language would then allow you to express these patterns in a more compact manner than would be possible by other means of abstraction. Not only could this buck the trend of ever-growing applications, it would actually allow the code base to shrink during the course of development!
One result from the STEPS program that I find particularly impressive was Nile, a little language for describing graphics rendering and compositing. The goal was to use Nile to reach feature parity with Cairo–an open-source renderer used in various free software projects–which weighs in at about 44 000 lines of code. The Nile equivalent ended up being about 300 lines. 2
Why not high-level languages?
Nevertheless, Ada will not prove to be the silver bullet that slays the software productivity monster. It is, after all, just another high-level language, and the biggest payoff from such languages came from the first transition, up from the accidental complexities of the machine into the more abstract statement of step-by-step solutions. Once those accidents have been removed, the remaining ones are smaller, and the payoff from their removal will surely be less.
– Frederick P. Brooks, No Silver Bullet
“Hey, wait a minute” you might say “why can’t we just invent a higher-level, general-purpose language?” Personally, I believe we have reached diminishing returns for the expressiveness of general-purpose languages. If there is a higher level, what would it even look like? Take Python, for example–it’s so high-level it pretty much looks like pseudocode already. 3
The problem with general-purpose languages is that you still have to translate your problem to an algorithm, and then express the algorithm in your target language. Now, high-level languages are great at describing algorithms, but unless the goal was to implement the algorithm then it’s just accidental complexity.
Writing this post reminded me of a story about Donald Knuth: Knuth had been asked to demonstrate his literate programming style in Jon Bentley’s Programming Pearls column; Doug McIlroy was also invited to provide critique of Knuth’s program. 4 The task at hand was to count word frequencies in a given text.
Knuth’s solution was meticulously written in WEB, his own literate programming variant of Pascal. He had even included a purpose-built data structure just for keeping track of word counts, and it all fit within ten pages of code. While McIlroy was quick to praise the craftsmanship of Knuth’s solution, he was not very impressed with the program itself. As part of his critique, he wrote his own solution in a creole of shell script, Unix commands and little languages:
tr -cs A-Za-z '\n' |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}q
While it might not the most readable code for non-Unix hackers–and McIlroy would probably admit as much, as he saw fit to include an annotated version– this summary response is arguably easier to understand than a ten-page program.
Unix commands are designed for manipulating text, which is why it’s possible to write such a compact word-counting program–maybe shell script could be considered the “Del notation” of text manipulation?
Less is more
The Unix command example above illustrates another characteristic of little languages: Less powerful languages and more powerful runtimes. Gonzalez had noted the following trend in The end of history for programming:
A common pattern emerges when we study the above trends:
- Push a userland concern into a runtime concern, which:
- … makes programs more closely resemble pure mathematical expressions, and:
- … significantly increases the complexity of the runtime.
Regular expressions and SQL won’t let you express anything but text search and database operations, respectively. This is in contrast to a language like C where there is no runtime and you can express anything that’s possible on a von Neumann architecture. High-level languages like Python and Haskell fall somewhere in between: Memory management is handled for you, but you still have the full power of a Turing-complete language at your disposal, which means you can express any computation possible.
Little languages are at the opposite end of the power spectrum from C: Not only is the architecture of the computer abstracted away, but some of these languages also limit the kinds of program you can express–they’re Turing-incomplete by design. This might sound awfully limiting, but in fact it opens up a whole new dimension of possibilities for optimization and static analysis. And, like abstracting away memory management erases a whole class of bugs, it might be possible to erase yet more bugs by abstracting away as much of the algorithmic work as possible.
Static analysis
Less powerful languages are easier to reason about, and can provide stronger guarantees than general-purpose languages. For example, Dhall is a total functional programming language for generating configuration files. Since you don’t want to risk crashing your deployment scripts or putting them into an infinite loop, Dhall programs are guaranteed to:
- Not crash, and
- Terminate in a finite amount of time.
The first point is accomplished by not throwing exceptions; any operation that
can fail (e.g. getting the first element of a potentially empty list) returns
an Optional result, which may or may not contain a value. The second
point–guaranteed termination–is accomplished by not allowing recursive
definitions 5. In other functional programming languages recursion
is the primary way you would express loops, but in Dhall you have to rely on
the built-in fold function instead. The lack of a general loop construct also
means Dhall is not Turing-complete; but since it’s not a general-purpose
programming language it doesn’t need to be (unlike CSS, apparently
6).
If the languages are small, reasoning about them becomes even easier. For
example, to determine whether an arbitrary Python program is free of
side-effects is hard, but in SQL it’s trivial–just check if the query starts
with SELECT 7.
For Nile, the STEPS team saw the need for a graphical debugger 8. Bret Victor (yes, the Bret Victor of Inventing on Principle fame) came up with a tool that would tell you the exact lines of code that was involved in drawing a specific pixel on the screen. You can watch Alan Kay demo it on YouTube, but you can also try it yourself. Tools like these are possible because Nile is a small language that’s easy to reason about–imagine trying to do the same thing with graphics code written in C++!
The need for speed
More powerful programming languages not only increase the potential for bugs, it can also be detrimental to performance. For example, if a program isn’t expressed in terms of an algorithm, the runtime is free to choose its own; slow expressions can be substituted for faster ones if we can prove that they produce the same result.
For example, a SQL query doesn’t dictate how a query should be executed–the database engine is free to use whichever query plan it deems most appropriate, e.g. whether it should use an index, a combination of indices, or just scan the entire database table. Modern database engines also collect statistics on the value distributions of its columns, so they can choose a statistically optimal query plan on the fly. This wouldn’t be possible if the query was described by the way of an algorithm.
One part of the “secret sauce” that allowed the Nile language to be so compact was Jitblt, a just-in-time compiler for graphics rendering. From discussions between the STEPS and Cairo teams it became clear that a lot of the Cairo code was dedicated to hand-optimization of pixel compositing operations; work that could, in theory, be offloaded to a compiler. Dan Amelang from the Cairo team volunteered to implement such a compiler, and the result was Jitblt. This meant that the optimization work in the graphics pipeline could be decoupled from the purely mathematical descriptions of what to render, which allowed Nile to run about as fast as the original, hand-optimized Cairo code. 9
Small languages, big potential
So what happened with the STEPS project? Did they end up with the code equivalent of “3 cubic miles of case law”, or did they manage to create an operating system small enough to fit on a t-shirt? The end result of STEPS was KSWorld, a complete operating system including both a document editor and spreadsheet editor, which ended up being about 17 000 lines of code 10. While you would need a really big t-shirt to fit all of that in, I would still call it a success.
The creation of KSWorld seems to indicate that there’s big potential in little languages. However, there are still many unanswered questions, such as: How should these little languages talk to each other? Should they compile to a common intermediate representation? Or should different runtimes exist in parallel and communicate with each other via a common protocol (e.g. UNIX pipes or TCP/IP)? Or maybe each language is small enough to be re-implemented in a variety of different host languages (like regular expressions)? Maybe the way forward is a combination of all of these? In any case, I’m convinced that we need to come up with a different way of building software. Maybe little languages will be part of that story, or maybe they won’t–the important thing is that we stop trying to pile bricks on top of each other for long enough to come up with something better.
Further reading
- Connexion is an open-source API framework from Zazzle; what makes it stand out is that it can generate endpoints automatically from an OpenAPI spec; usually you would use OpenAPI to describe the endpoints of an existing HTTP service, but Connexion does it the other way around: Given an OpenAPI schema it will set up an API server with endpoints, validation logic and live documentation.
- Catala is a declarative language for translating law text into an executable specification. Because it supports non-monotonic reasoning (i.e. a later statement can cancel out or further qualify a previous statement) it allows expressing programs in much the same way legal texts are written, e.g. as a set of statements that can be amended or extended by adding new statements.
- Racket is a Lisp dialect that’s specifically designed for creating new languages (a technique sometimes referred to as language-oriented programming). I haven’t had time to play around much with Racket myself, but it looks like a very suitable tool for creating “little languages”. If you’re curious, you can check out the Creating Languages in Racket tutorial.
- While the STEPS project wrapped up in 2018, all the results are available online at the VPRI Writings page.
-
See https://www.phoronix.com/news/Linux-Git-Stats-EOY2019 ↩︎
-
STEPS 2009 Progress Report, p. 4-6 ↩︎
-
To quote Peter Norvig: “I came to Python not because I thought it was a better / acceptable / pragmatic Lisp, but because it was better pseudocode.” See: https://news.ycombinator.com/item?id=1803815 ↩︎
-
Programming Pearls, in Communications of the ACM June 1986 ↩︎
-
There’s an interesting Hacker News thread about recursion in Dhall here: https://news.ycombinator.com/item?id=15187150 ↩︎
-
Yes, it does look like CSS is Turing-complete ↩︎
-
Warranty void if you don’t stick to ISO SQL ↩︎
-
STEPS 2012 Final Report, p. 12 ↩︎
-
STEPS 2012 Final Report, p. 32 ↩︎